搜索到
9
篇与
小雷debug
的结果
-
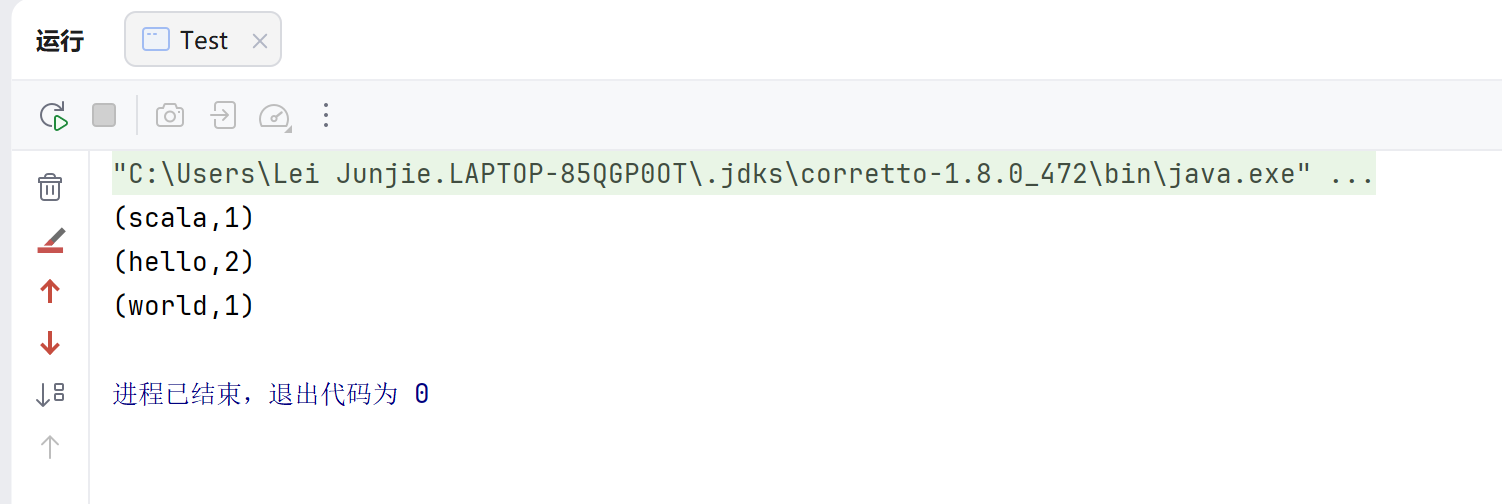
 Spark快速入门 Spark maven依赖配置<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.xzlei</groupId> <artifactId>featureEngineering</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> <build> <plugins> <!-- 该插件用于将 Scala 代码编译成 class 文件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.1.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </plugin> </plugins> </build> </project>最简单的入门程序请先创建一个项目,然后导入相应依赖,在项目根目录下创建一个datas文件夹用来存放数据文件,在datas目录下创建一个1.txt,输入如下数据:hello word hello scala hello sparkpackage cn.xzlei.test import org.apache.spark.{SparkConf, SparkContext} object Test { def main(args: Array[String]): Unit = { // 创建Spark配置项 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Test") // 根据配置项创建Spark上下文执行环境 val sc = new SparkContext(sparkConf) // 读取文本文件datas/1.txt val wordText = sc.textFile("datas/1.txt") // 根据flatMap扁平化操作根据空格进行单词分割,("hello","word","hello") val words = wordText.flatMap(_.split(" ")) // 调用map函数进行映射,转为(String,Int)类型:(hello,1) val wordByOne = words.map(item => (item, 1)) // 调用reduceByKey方法进行聚合操作 wordByOne.reduceByKey(_+_).foreach(println) sc.stop() } } 运行效果如下:RDD转换算子RDD根据数据处理方式的不同将算子整体上分为Value类型、双Value类型和Key-Value类型Value类型map函数签名:def map[U: ClassTag](f: T => U): RDD[U]函数说明:将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。示例代码:val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD1: RDD[Int] = dataRDD.map(num => { num * 2 }) val dataRDD2: RDD[String] = dataRDD1.map(num => { "" + num })flatMap函数签名:def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]函数说明:将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射示例代码:val dataRDD = sparkContext.makeRDD(List( List(1,2),List(3,4) ),1) val dataRDD1 = dataRDD.flatMap( list => list )groupBy函数签名:def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]函数说明:将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为shuffle。极限情况下,数据可能被分在同一个分区中,一个组的数据在一个分区中,但是并不是说一个分区中只有一个组示例代码:val dataRDD = sparkContext.makeRDD(List(1,2,3,4),1) val dataRDD1 = dataRDD.groupBy( _%2 )filter函数签名:def filter(f: T => Boolean): RDD[T]函数说明:将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4 ),1) val dataRDD1 = dataRDD.filter(_%2 == 0)sample函数签名:def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T]函数说明:根据指定的规则从数据集中抽取数据示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4 ),1) // 抽取数据不放回(伯努利算法) // 伯努利算法:又叫 0、1 分布。例如扔硬币,要么正面,要么反面。 // 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不 要 // 第一个参数:抽取的数据是否放回,false:不放回 // 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取; // 第三个参数:随机数种子 val dataRDD1 = dataRDD.sample(false, 0.5) // 抽取数据放回(泊松算法) // 第一个参数:抽取的数据是否放回,true:放回;false:不放回 // 第二个参数:重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数 // 第三个参数:随机数种子 val dataRDD2 = dataRDD.sample(true, 2)distinct函数签名:def distinct()(implicit ord: Ordering[T] = null): RDD[T] def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]函数说明:将数据集中的重复数据去重示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4,1,2 ),1) val dataRDD1 = dataRDD.distinct() val dataRDD2 = dataRDD.distinct(2)sortBy函数签名:def sortBy[K]( f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]函数说明:该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。中间存在 shuffle 的过程示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4,1,2 ),2) val dataRDD1 = dataRDD.sortBy(num=>num, false, 4)双Value类型intersection函数签名:def intersection(other: RDD[T]): RDD[T]函数说明:对源 RDD 和参数RDD求交集后返回一个新的 RDD示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.intersection(dataRDD2)union函数签名:def union(other: RDD[T]): RDD[T]函数说明:对源 RDD 和参数 RDD 求并集后返回一个新的 RDD示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.union(dataRDD2)subtract函数签名:def subtract(other: RDD[T]): RDD[T]函数说明:以一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来。求差集示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.subtract(dataRDD2)zip函数签名:def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]函数说明:将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD 中的元素,Value 为第 2 个 RDD 中的相同位置的元素。示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.zip(dataRDD2)key-value类型partitionBy函数签名:def partitionBy(partitioner: Partitioner): RDD[(K, V)]函数说明:将数据按照指定 Partitioner 重新进行分区。Spark 默认的分区器是 HashPartitioner示例代码:val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3) import org.apache.spark.HashPartitioner val rdd2: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(2))reduceByKey函数签名:def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]函数说明:可以将数据按照相同的 Key 对 Value 进行聚合示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.reduceByKey(_+_) val dataRDD3 = dataRDD1.reduceByKey(_+_, 2)groupByKey函数签名:def groupByKey(): RDD[(K, Iterable[V])] def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]函数说明:将数据源的数据根据 key 对 value 进行分组示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.groupByKey() val dataRDD3 = dataRDD1.groupByKey(2) val dataRDD4 = dataRDD1.groupByKey(new HashPartitioner(2))从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的 数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较 高。 从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚 合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那 么还是只能使用 groupByKeyaggregateByKey函数签名:def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]函数说明:将数据根据不同的规则进行分区内计算和分区间计算示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.aggregateByKey(0)(_+_,_+_)❖ 取出每个分区内相同 key 的最大值然后分区间相加// TODO : 取出每个分区内相同 key 的最大值然后分区间相加 // aggregateByKey 算子是函数柯里化,存在两个参数列表 // 1. 第一个参数列表中的参数表示初始值 // 2. 第二个参数列表中含有两个参数 // 2.1 第一个参数表示分区内的计算规则 // 2.2 第二个参数表示分区间的计算规则 val rdd = sc.makeRDD(List( ("a",1),("a",2),("c",3), ("b",4),("c",5),("c",6) ),2) // 0:("a",1),("a",2),("c",3) => (a,10)(c,10) // => (a,10)(b,10)(c,20) // 1:("b",4),("c",5),("c",6) => (b,10)(c,10) val resultRDD = rdd.aggregateByKey(10)( (x, y) => math.max(x,y), (x, y) => x + y ) resultRDD.collect().foreach(println)foldByKey函数签名:def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]函数说明:当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.foldByKey(0)(_+_)ssortByKey函数签名:def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length) : RDD[(K, V)]函数说明:在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序 的示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(true) val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(false)join函数签名:def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]函数说明:在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的 (K,(V,W))的 RDD示例代码:val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c"))) val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (3, 6))) rdd.join(rdd1).collect().foreach(println)leftOuterJoin函数签名:def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]函数说明:类似于 SQL 语句的左外连接示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val rdd: RDD[(String, (Int, Option[Int]))] = dataRDD1.leftOuterJoin(dataRDD2)cogroup函数签名:def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]函数说明:在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("a",2),("c",3))) val dataRDD2 = sparkContext.makeRDD(List(("a",1),("c",2),("c",3))) val value: RDD[(String, (Iterable[Int], Iterable[Int]))] = dataRDD1.cogroup(dataRDD2)RDD行动算子reduce函数签名:def reduce(f: (T, T) => T): T函数说明:聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 聚合数据 val reduceResult: Int = rdd.reduce(_+_)collect函数签名:def collect(): Array[T]函数说明:在驱动程序中,以数组 Array 的形式返回数据集的所有元素示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 收集数据到 Driver rdd.collect().foreach(println)count函数签名:def count(): Long函数说明:返回 RDD 中元素的个数示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 返回 RDD 中元素的个数 val countResult: Long = rdd.count()first函数签名:def first(): T函数说明:返回 RDD 中的第一个元素示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) val firstResult: Int = rdd.first() println(firstResult)take函数签名:def take(num: Int): Array[T]函数说明:返回一个由 RDD 的前 n 个元素组成的数组示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) val takeResult: Array[Int] = rdd.take(2) println(takeResult.mkString(","))takeOrdered函数签名:def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]函数说明:返回该 RDD 排序后的前 n 个元素组成的数组示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4)) val result: Array[Int] = rdd.takeOrdered(2)aggregate函数签名:def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U函数说明:分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8) // 将该 RDD 所有元素相加得到结果 //val result: Int = rdd.aggregate(0)(_ + _, _ + _) val result: Int = rdd.aggregate(10)(_ + _, _ + _)fold函数签名:def fold(zeroValue: T)(op: (T, T) => T): T函数说明:折叠操作,aggregate 的简化版操作示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val foldResult: Int = rdd.fold(0)(_+_)countByKey函数签名:def countByKey(): Map[K, Long]函数说明:统计每种 key 的个数示例代码:val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c"))) // 统计每种 key 的个数 val result: collection.Map[Int, Long] = rdd.countByKey()save 相关算子函数签名:def saveAsTextFile(path: String): Unit def saveAsObjectFile(path: String): Unit def saveAsSequenceFile( path: String, codec: Option[Class[_ <: CompressionCodec]] = None): Unit函数说明:将数据保存到不同格式的文件中示例代码:// 保存成 Text 文件 rdd.saveAsTextFile("output") // 序列化成对象保存到文件 rdd.saveAsObjectFile("output1") // 保存成 Sequencefile 文件 rdd.map((_,1)).saveAsSequenceFile("output2")foreach函数签名:def foreach(f: T => Unit): Unit = withScope { val cleanF = sc.clean(f) sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF)) }函数说明:分布式遍历 RDD 中的每一个元素,调用指定函数示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 收集后打印 rdd.map(num=>num).collect().foreach(println) println("****************") // 分布式打印 rdd.foreach(println)累加器实现原理累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在 Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后, 传回 Driver 端进行 merge。基础编程系统累加器val rdd = sc.makeRDD(List(1,2,3,4,5)) // 声明累加器 var sum = sc.longAccumulator("sum"); rdd.foreach( num => { // 使用累加器 sum.add(num) } ) // 获取累加器的值 println("sum = " + sum.value)自定义累加器// 自定义累加器 // 1. 继承 AccumulatorV2,并设定泛型 // 2. 重写累加器的抽象方法 class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]]{ var map : mutable.Map[String, Long] = mutable.Map() // 累加器是否为初始状态 override def isZero: Boolean = { map.isEmpty } // 复制累加器 override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = { new WordCountAccumulator } // 重置累加器 override def reset(): Unit = { map.clear() } // 向累加器中增加数据 (In) override def add(word: String): Unit = { // 查询 map 中是否存在相同的单词 // 如果有相同的单词,那么单词的数量加 1 // 如果没有相同的单词,那么在 map 中增加这个单词 map(word) = map.getOrElse(word, 0L) + 1L } // 合并累加器 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { val map1 = map val map2 = other.value // 两个 Map 的合并 map = map1.foldLeft(map2)( ( innerMap, kv ) => { innerMap(kv._1) = innerMap.getOrElse(kv._1, 0L) + kv._2 innerMap } ) } // 返回累加器的结果 (Out) override def value: mutable.Map[String, Long] = map }广播变量实现原理广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个 或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表, 广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务 分别发送。基础编程val rdd1 = sc.makeRDD(List( ("a",1), ("b", 2), ("c", 3), ("d", 4) ),4) val list = List( ("a",4), ("b", 5), ("c", 6), ("d", 7) ) // 声明广播变量 val broadcast: Broadcast[List[(String, Int)]] = sc.broadcast(list) val resultRDD: RDD[(String, (Int, Int))] = rdd1.map { case (key, num) => { var num2 = 0 // 使用广播变量 for ((k, v) <- broadcast.value) { if (k == key) { num2 = v } } (key, (num, num2)) } }
Spark快速入门 Spark maven依赖配置<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.xzlei</groupId> <artifactId>featureEngineering</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> <build> <plugins> <!-- 该插件用于将 Scala 代码编译成 class 文件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.1.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </plugin> </plugins> </build> </project>最简单的入门程序请先创建一个项目,然后导入相应依赖,在项目根目录下创建一个datas文件夹用来存放数据文件,在datas目录下创建一个1.txt,输入如下数据:hello word hello scala hello sparkpackage cn.xzlei.test import org.apache.spark.{SparkConf, SparkContext} object Test { def main(args: Array[String]): Unit = { // 创建Spark配置项 val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Test") // 根据配置项创建Spark上下文执行环境 val sc = new SparkContext(sparkConf) // 读取文本文件datas/1.txt val wordText = sc.textFile("datas/1.txt") // 根据flatMap扁平化操作根据空格进行单词分割,("hello","word","hello") val words = wordText.flatMap(_.split(" ")) // 调用map函数进行映射,转为(String,Int)类型:(hello,1) val wordByOne = words.map(item => (item, 1)) // 调用reduceByKey方法进行聚合操作 wordByOne.reduceByKey(_+_).foreach(println) sc.stop() } } 运行效果如下:RDD转换算子RDD根据数据处理方式的不同将算子整体上分为Value类型、双Value类型和Key-Value类型Value类型map函数签名:def map[U: ClassTag](f: T => U): RDD[U]函数说明:将处理的数据逐条进行映射转换,这里的转换可以是类型的转换,也可以是值的转换。示例代码:val dataRDD: RDD[Int] = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD1: RDD[Int] = dataRDD.map(num => { num * 2 }) val dataRDD2: RDD[String] = dataRDD1.map(num => { "" + num })flatMap函数签名:def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]函数说明:将处理的数据进行扁平化后再进行映射处理,所以算子也称之为扁平映射示例代码:val dataRDD = sparkContext.makeRDD(List( List(1,2),List(3,4) ),1) val dataRDD1 = dataRDD.flatMap( list => list )groupBy函数签名:def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])]函数说明:将数据根据指定的规则进行分组, 分区默认不变,但是数据会被打乱重新组合,我们将这样的操作称之为shuffle。极限情况下,数据可能被分在同一个分区中,一个组的数据在一个分区中,但是并不是说一个分区中只有一个组示例代码:val dataRDD = sparkContext.makeRDD(List(1,2,3,4),1) val dataRDD1 = dataRDD.groupBy( _%2 )filter函数签名:def filter(f: T => Boolean): RDD[T]函数说明:将数据根据指定的规则进行筛选过滤,符合规则的数据保留,不符合规则的数据丢弃。当数据进行筛选过滤后,分区不变,但是分区内的数据可能不均衡,生产环境下,可能会出现数据倾斜。示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4 ),1) val dataRDD1 = dataRDD.filter(_%2 == 0)sample函数签名:def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T]函数说明:根据指定的规则从数据集中抽取数据示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4 ),1) // 抽取数据不放回(伯努利算法) // 伯努利算法:又叫 0、1 分布。例如扔硬币,要么正面,要么反面。 // 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不 要 // 第一个参数:抽取的数据是否放回,false:不放回 // 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取; // 第三个参数:随机数种子 val dataRDD1 = dataRDD.sample(false, 0.5) // 抽取数据放回(泊松算法) // 第一个参数:抽取的数据是否放回,true:放回;false:不放回 // 第二个参数:重复数据的几率,范围大于等于 0.表示每一个元素被期望抽取到的次数 // 第三个参数:随机数种子 val dataRDD2 = dataRDD.sample(true, 2)distinct函数签名:def distinct()(implicit ord: Ordering[T] = null): RDD[T] def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]函数说明:将数据集中的重复数据去重示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4,1,2 ),1) val dataRDD1 = dataRDD.distinct() val dataRDD2 = dataRDD.distinct(2)sortBy函数签名:def sortBy[K]( f: (T) => K, ascending: Boolean = true, numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]函数说明:该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。中间存在 shuffle 的过程示例代码:val dataRDD = sparkContext.makeRDD(List( 1,2,3,4,1,2 ),2) val dataRDD1 = dataRDD.sortBy(num=>num, false, 4)双Value类型intersection函数签名:def intersection(other: RDD[T]): RDD[T]函数说明:对源 RDD 和参数RDD求交集后返回一个新的 RDD示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.intersection(dataRDD2)union函数签名:def union(other: RDD[T]): RDD[T]函数说明:对源 RDD 和参数 RDD 求并集后返回一个新的 RDD示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.union(dataRDD2)subtract函数签名:def subtract(other: RDD[T]): RDD[T]函数说明:以一个 RDD 元素为主,去除两个 RDD 中重复元素,将其他元素保留下来。求差集示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.subtract(dataRDD2)zip函数签名:def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]函数说明:将两个 RDD 中的元素,以键值对的形式进行合并。其中,键值对中的 Key 为第 1 个 RDD 中的元素,Value 为第 2 个 RDD 中的相同位置的元素。示例代码:val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4)) val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6)) val dataRDD = dataRDD1.zip(dataRDD2)key-value类型partitionBy函数签名:def partitionBy(partitioner: Partitioner): RDD[(K, V)]函数说明:将数据按照指定 Partitioner 重新进行分区。Spark 默认的分区器是 HashPartitioner示例代码:val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"aaa"),(2,"bbb"),(3,"ccc")),3) import org.apache.spark.HashPartitioner val rdd2: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(2))reduceByKey函数签名:def reduceByKey(func: (V, V) => V): RDD[(K, V)] def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]函数说明:可以将数据按照相同的 Key 对 Value 进行聚合示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.reduceByKey(_+_) val dataRDD3 = dataRDD1.reduceByKey(_+_, 2)groupByKey函数签名:def groupByKey(): RDD[(K, Iterable[V])] def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]函数说明:将数据源的数据根据 key 对 value 进行分组示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.groupByKey() val dataRDD3 = dataRDD1.groupByKey(2) val dataRDD4 = dataRDD1.groupByKey(new HashPartitioner(2))从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的 数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较 高。 从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚 合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那 么还是只能使用 groupByKeyaggregateByKey函数签名:def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]函数说明:将数据根据不同的规则进行分区内计算和分区间计算示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.aggregateByKey(0)(_+_,_+_)❖ 取出每个分区内相同 key 的最大值然后分区间相加// TODO : 取出每个分区内相同 key 的最大值然后分区间相加 // aggregateByKey 算子是函数柯里化,存在两个参数列表 // 1. 第一个参数列表中的参数表示初始值 // 2. 第二个参数列表中含有两个参数 // 2.1 第一个参数表示分区内的计算规则 // 2.2 第二个参数表示分区间的计算规则 val rdd = sc.makeRDD(List( ("a",1),("a",2),("c",3), ("b",4),("c",5),("c",6) ),2) // 0:("a",1),("a",2),("c",3) => (a,10)(c,10) // => (a,10)(b,10)(c,20) // 1:("b",4),("c",5),("c",6) => (b,10)(c,10) val resultRDD = rdd.aggregateByKey(10)( (x, y) => math.max(x,y), (x, y) => x + y ) resultRDD.collect().foreach(println)foldByKey函数签名:def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]函数说明:当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = dataRDD1.foldByKey(0)(_+_)ssortByKey函数签名:def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length) : RDD[(K, V)]函数说明:在一个(K,V)的 RDD 上调用,K 必须实现 Ordered 接口(特质),返回一个按照 key 进行排序 的示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(true) val sortRDD1: RDD[(String, Int)] = dataRDD1.sortByKey(false)join函数签名:def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]函数说明:在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的 (K,(V,W))的 RDD示例代码:val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c"))) val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (3, 6))) rdd.join(rdd1).collect().foreach(println)leftOuterJoin函数签名:def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]函数说明:类似于 SQL 语句的左外连接示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val dataRDD2 = sparkContext.makeRDD(List(("a",1),("b",2),("c",3))) val rdd: RDD[(String, (Int, Option[Int]))] = dataRDD1.leftOuterJoin(dataRDD2)cogroup函数签名:def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]函数说明:在类型为(K,V)和(K,W)的 RDD 上调用,返回一个(K,(Iterable,Iterable))类型的 RDD示例代码:val dataRDD1 = sparkContext.makeRDD(List(("a",1),("a",2),("c",3))) val dataRDD2 = sparkContext.makeRDD(List(("a",1),("c",2),("c",3))) val value: RDD[(String, (Iterable[Int], Iterable[Int]))] = dataRDD1.cogroup(dataRDD2)RDD行动算子reduce函数签名:def reduce(f: (T, T) => T): T函数说明:聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 聚合数据 val reduceResult: Int = rdd.reduce(_+_)collect函数签名:def collect(): Array[T]函数说明:在驱动程序中,以数组 Array 的形式返回数据集的所有元素示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 收集数据到 Driver rdd.collect().foreach(println)count函数签名:def count(): Long函数说明:返回 RDD 中元素的个数示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 返回 RDD 中元素的个数 val countResult: Long = rdd.count()first函数签名:def first(): T函数说明:返回 RDD 中的第一个元素示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) val firstResult: Int = rdd.first() println(firstResult)take函数签名:def take(num: Int): Array[T]函数说明:返回一个由 RDD 的前 n 个元素组成的数组示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) val takeResult: Array[Int] = rdd.take(2) println(takeResult.mkString(","))takeOrdered函数签名:def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]函数说明:返回该 RDD 排序后的前 n 个元素组成的数组示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,3,2,4)) val result: Array[Int] = rdd.takeOrdered(2)aggregate函数签名:def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U函数说明:分区的数据通过初始值和分区内的数据进行聚合,然后再和初始值进行分区间的数据聚合示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 8) // 将该 RDD 所有元素相加得到结果 //val result: Int = rdd.aggregate(0)(_ + _, _ + _) val result: Int = rdd.aggregate(10)(_ + _, _ + _)fold函数签名:def fold(zeroValue: T)(op: (T, T) => T): T函数说明:折叠操作,aggregate 的简化版操作示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4)) val foldResult: Int = rdd.fold(0)(_+_)countByKey函数签名:def countByKey(): Map[K, Long]函数说明:统计每种 key 的个数示例代码:val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c"))) // 统计每种 key 的个数 val result: collection.Map[Int, Long] = rdd.countByKey()save 相关算子函数签名:def saveAsTextFile(path: String): Unit def saveAsObjectFile(path: String): Unit def saveAsSequenceFile( path: String, codec: Option[Class[_ <: CompressionCodec]] = None): Unit函数说明:将数据保存到不同格式的文件中示例代码:// 保存成 Text 文件 rdd.saveAsTextFile("output") // 序列化成对象保存到文件 rdd.saveAsObjectFile("output1") // 保存成 Sequencefile 文件 rdd.map((_,1)).saveAsSequenceFile("output2")foreach函数签名:def foreach(f: T => Unit): Unit = withScope { val cleanF = sc.clean(f) sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF)) }函数说明:分布式遍历 RDD 中的每一个元素,调用指定函数示例代码:val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4)) // 收集后打印 rdd.map(num=>num).collect().foreach(println) println("****************") // 分布式打印 rdd.foreach(println)累加器实现原理累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在 Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后, 传回 Driver 端进行 merge。基础编程系统累加器val rdd = sc.makeRDD(List(1,2,3,4,5)) // 声明累加器 var sum = sc.longAccumulator("sum"); rdd.foreach( num => { // 使用累加器 sum.add(num) } ) // 获取累加器的值 println("sum = " + sum.value)自定义累加器// 自定义累加器 // 1. 继承 AccumulatorV2,并设定泛型 // 2. 重写累加器的抽象方法 class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]]{ var map : mutable.Map[String, Long] = mutable.Map() // 累加器是否为初始状态 override def isZero: Boolean = { map.isEmpty } // 复制累加器 override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = { new WordCountAccumulator } // 重置累加器 override def reset(): Unit = { map.clear() } // 向累加器中增加数据 (In) override def add(word: String): Unit = { // 查询 map 中是否存在相同的单词 // 如果有相同的单词,那么单词的数量加 1 // 如果没有相同的单词,那么在 map 中增加这个单词 map(word) = map.getOrElse(word, 0L) + 1L } // 合并累加器 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { val map1 = map val map2 = other.value // 两个 Map 的合并 map = map1.foldLeft(map2)( ( innerMap, kv ) => { innerMap(kv._1) = innerMap.getOrElse(kv._1, 0L) + kv._2 innerMap } ) } // 返回累加器的结果 (Out) override def value: mutable.Map[String, Long] = map }广播变量实现原理广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个 或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表, 广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务 分别发送。基础编程val rdd1 = sc.makeRDD(List( ("a",1), ("b", 2), ("c", 3), ("d", 4) ),4) val list = List( ("a",4), ("b", 5), ("c", 6), ("d", 7) ) // 声明广播变量 val broadcast: Broadcast[List[(String, Int)]] = sc.broadcast(list) val resultRDD: RDD[(String, (Int, Int))] = rdd1.map { case (key, num) => { var num2 = 0 // 使用广播变量 for ((k, v) <- broadcast.value) { if (k == key) { num2 = v } } (key, (num, num2)) } } -
用百度统计为你的博客赋能 百度统计是百度官方推出的免费网站分析工具,它不仅能实时监控访客行为,还能深入洞察用户来源、浏览路径、关键词偏好等关键指标。对于博主而言,掌握百度统计的使用方法,意味着你可以基于真实数据优化内容策略、提升用户体验,甚至提高广告转化率。本文将手把手带你完成从注册安装到核心数据分析再到实战优化建议的全过程快速上手:五步完成百度统计部署使用百度统计非常简单,只需三个步骤:1. 注册/登录账号访问 https://tongji.baidu.com,使用百度账号登录2. 添加你的博客站点进入百度统计后台页面,在“ 使用设置 > 网站列表 ”中点击“ 新增网站 ”,填写博客的完整域名(如 https://yourblog.com),务必与实际访问地址一致(是否带 www、协议是 http 还是 https 都要统一)。3. 嵌入百度统计JS脚本新增完网站后会自动跳转到代码获取页面系统会生成一段 JavaScript 跟踪代码(推荐使用异步加载版本),你需要将其粘贴到博客所有页面的 标签内。如果你使用的是 WordPress,可通过主题编辑器或插件(如 “Insert Headers and Footers”)轻松完成。⏱️ 安装完成后,等待约20分钟至几小时,即可在后台看到实时访客数据。4. 检查脚本状态5. 查看网站概况其他功能自行研究,这里就不在说了,如果有啥不懂的,欢迎到评论区留言哈😄
-
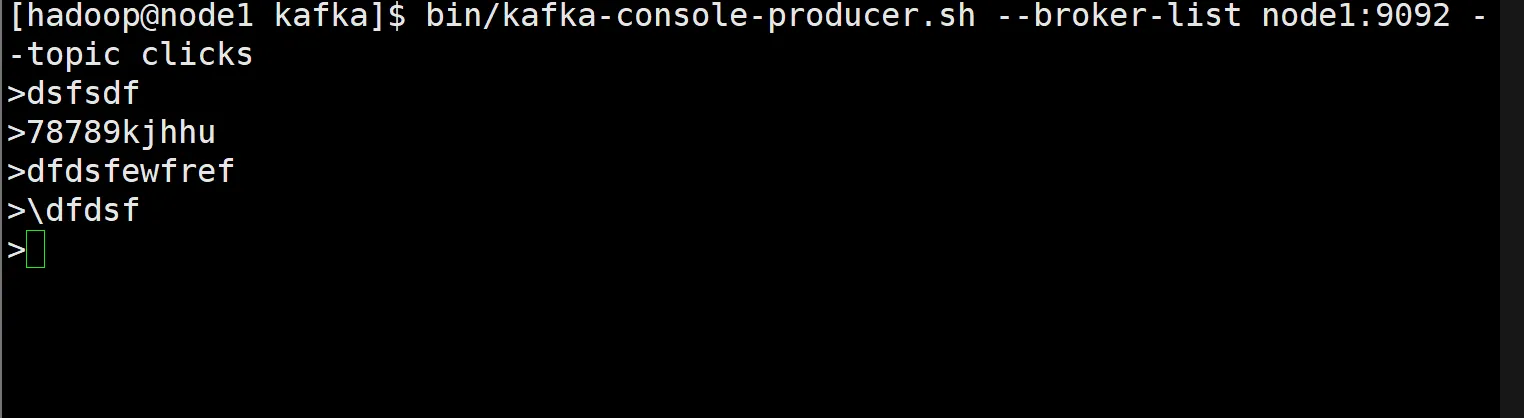
Flink快速入门 {music-list id="3136952023" color="#1989fa" autoplay="autoplay"/}Flink命令行提交任务启动集群bin/start-cluster.sh在 node1 中执行以下命令启动 netcat。nc -lk 7777进入到 Flink 的安装路径下,在命令行使用 flink run 命令提交作业。./bin/flink run -m node1:8081 -c cn.xzlei.chap02.StreamWordCount ./flumeDemo-1.0-SNAPSHOT.jar -param --host node1 --port 7777参数: –m 指定了提交到的 JobManager,-c 指定了入口类-param 指定了jar的自定义参数查看指定任务信息bin/flink-cluster.sh list [taskID]查看所有任务信息bin/flink-cluster.sh list读取有界数据package cn.xzlei.chap05 import org.apache.flink.streaming.api.scala._ import java.util.Date case class Event(user:String,url:String,timestamp:Long) object SourceBoundedTest { def main(args: Array[String]): Unit = { // 创建一个执行环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 设置并行数量为1 env.setParallelism(1) // 创建一个数据列表 val list:List[Event] = List( Event("Piter", "./home?id=5", new Date().getTime), Event("Mary", "./shop?id=8", new Date().getTime), Event("Jack", "./userCenter?id=78", new Date().getTime), ) // 从集合中获取数据 val stream1 = env.fromCollection(list) // 从元素中获取数据 val stream2 = env.fromElements(1, 2, 3, 4, 5) // 从文本文件中获取数据 val stream3 = env.readTextFile("input/test.txt") stream1.print("stream1") stream2.print("number") stream3.print("stream3") env.execute() } } 读取Kafka数据添加pom.xml文件依赖:<!--Flink连接 Kafka相关依赖--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.12</artifactId> <version>1.14</version> </dependency>编写代码package cn.xzlei.chap05 import org.apache.flink.api.common.eventtime.WatermarkStrategy import org.apache.flink.api.common.serialization.SimpleStringSchema import org.apache.flink.connector.kafka.source.KafkaSource import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer import org.apache.flink.streaming.api.scala._ import java.util.Properties object SourceKafkaTest { def main(args: Array[String]): Unit = { // 创建一个流处理环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 创建一个sourceKafka连接源 val kafkaSource = KafkaSource.builder[String]() .setBootstrapServers("node1:9092") .setTopics("clicks") .setGroupId("consumer-group") .setValueOnlyDeserializer(new SimpleStringSchema()) // .setStartingOffsets(OffsetsInitializer.latest()) .build() val stream:DataStream[String] = env.fromSource(kafkaSource,WatermarkStrategy.noWatermarks(),"kafkaSource") stream.print() env.execute() } }启动zookeeper、hadoop集群、Kafka集群[hadoop@node1 zookeeper-3.5.7]$ bin/zkServer.sh start [hadoop@node2 zookeeper-3.5.7]$ bin/zkServer.sh start [hadoop@node3 zookeeper-3.5.7]$ bin/zkServer.sh starthdfs --daemon start[hadoop@node1 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties [hadoop@node2 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties [hadoop@node3 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties在node1节点上打开生产者,指定topic主题为clicks# 如果没有创建主题,创建主题 [hadoop@node1 kafka]$ bin/kafka-topics.sh --bootstrap-server node1:9092 --create --topic clicks # 开启生产者 [hadoop@node1 kafka]$ bin/kafka-console-producer.sh --broker-list node1:9092 --topic clicks运行程序、在生产者中生产数据,观察控制台结果
-
2026新年快乐Python代码 今天是2026的第一天,新的一年,祝我们得偿所愿,平安喜乐,烟火漫漫,开心满满,八方来财,岁岁平安,万事尽可期待,一路好运常在,我们都要,越来越好!新年快乐~~下面是用Python编写的新年快乐代码:import pygame as pg import random as ra import math pg.init() pg.display.set_caption("🎇") winScreen = pg.display.Info() screenWidth = winScreen.current_w screenHeight = winScreen.current_h vector = pg.math.Vector2 trail_colors = [(45, 45, 45), (60, 60, 60), (75, 75, 75), (125, 125, 125), (150, 150, 150)] # 烟花类 class Firework: def __init__(self): # 随机生成颜色 self.colour = (ra.randint(0, 255), ra.randint(0, 255), ra.randint(0, 255)) # 随机生成三种颜色 self.colours = ( (ra.randint(0, 255), ra.randint(0, 255), ra.randint(0, 255)), (ra.randint(0, 255), ra.randint(0, 255), ra.randint(0, 255)), (ra.randint(0, 255), ra.randint(0, 255), ra.randint(0, 255)) ) # 生成一个表示发射出的火花的粒子对象 self.firework = Particle(ra.randint(0,screenWidth), screenHeight, True, self.colour) # 初始化爆炸状态为 False self.exploded = False self.particles = [] # 爆炸产生的粒子数量范围 self.min_max_particles = vector(666, 999) def update(self, win): g = vector(0, ra.uniform(0.15, 0.4)) if not self.exploded: # 给发射出的火花施加重力 self.firework.apply_force(g) self.firework.move() for tf in self.firework.trails: tf.show(win) self.show(win) if self.firework.vel.y >= 0: self.exploded = True self.explode() else: for particle in self.particles: # 给爆炸产生的粒子施加随机力 particle.apply_force(vector(g.x + ra.uniform(-1, 1) / 20, g.y / 2 + (ra.randint(1, 8) / 100))) particle.move() for t in particle.trails: t.show(win) particle.show(win) def explode(self): amount = ra.randint(int(self.min_max_particles.x), int(self.min_max_particles.y)) for i in range(amount): # 在爆炸位置生成粒子对象并添加到粒子列表中 self.particles.append(Particle(self.firework.pos.x, self.firework.pos.y, False, self.colours)) def show(self, win): # 绘制发射出的火花 pg.draw.circle(win, self.colour, (int(self.firework.pos.x), int(self.firework.pos.y)), self.firework.size) def remove(self): if self.exploded: for p in self.particles: if p.remove is True: self.particles.remove(p) if len(self.particles) == 0: return True else: return False # 粒子类 class Particle: def __init__(self, x, y, firework, colour): self.firework = firework self.pos = vector(x, y) self.origin = vector(x, y) self.radius = 25 self.remove = False self.explosion_radius = ra.randint(15, 25) self.life = 0 self.acc = vector(0, 0) self.trails = [] self.prev_posx = [-10] * 10 self.prev_posy = [-10] * 10 if self.firework: self.vel = vector(0, -ra.randint(17, 20)) self.size = 5 self.colour = colour for i in range(5): self.trails.append(Trail(i, self.size, True)) else: self.vel = vector(ra.uniform(-1, 1), ra.uniform(-1, 1)) self.vel.x *= ra.randint(7, self.explosion_radius + 2) self.vel.y *= ra.randint(7, self.explosion_radius + 2) self.size = ra.randint(2, 4) self.colour = ra.choice(colour) for i in range(5): self.trails.append(Trail(i, self.size, False)) def apply_force(self, force): # 施加力 self.acc += force def move(self): if not self.firework: # 爆炸产生的粒子减速 self.vel.x *= 0.8 self.vel.y *= 0.8 self.vel += self.acc self.pos += self.vel self.acc *= 0 if self.life == 0 and not self.firework: # 判断是否超出爆炸半径 distance = math.sqrt((self.pos.x - self.origin.x) ** 2 + (self.pos.y - self.origin.y) ** 2) if distance > self.explosion_radius: self.remove = True self.decay() self.trail_update() self.life += 1 def show(self, win): # 绘制粒子 pg.draw.circle(win, (self.colour[0], self.colour[1], self.colour[2], 0), (int(self.pos.x), int(self.pos.y)), self.size) def decay(self): if 50 > self.life > 10: ran = ra.randint(0, 30) if ran == 0: self.remove = True elif self.life > 50: ran = ra.randint(0, 5) if ran == 0: self.remove = True def trail_update(self): self.prev_posx.pop() self.prev_posx.insert(0, int(self.pos.x)) self.prev_posy.pop() self.prev_posy.insert(0, int(self.pos.y)) for n, t in enumerate(self.trails): if t.dynamic: t.get_pos(self.prev_posx[n + 1], self.prev_posy[n + 1]) else: t.get_pos(self.prev_posx[n + 5], self.prev_posy[n + 5]) # 痕迹类 class Trail: def __init__(self, n, size, dynamic): self.pos_in_line = n self.pos = vector(-10, -10) self.dynamic = dynamic if self.dynamic: self.colour = trail_colors[n] self.size = int(size - n / 2) else: self.colour = (255, 255, 200) self.size = size - 2 if self.size < 0: self.size = 0 def get_pos(self, x, y): self.pos = vector(x, y) def show(self, win): # 绘制痕迹 pg.draw.circle(win, self.colour, (int(self.pos.x), int(self.pos.y)), self.size) def update(win, fireworks): for fw in fireworks: fw.update(win) if fw.remove(): fireworks.remove(fw) pg.display.update() def fire(): screen = pg.display.set_mode((screenWidth, screenHeight - 66)) clock = pg.time.Clock() fireworks = [Firework() for i in range(2)] running = True # 加载字体 font = pg.font.SysFont("comicsansms", 99) # 渲染文本 text = "再见2025,你好2026" # 设置字体为支持中文的字体 font = pg.font.Font("C:/Windows/Fonts/msyh.ttc", 99) # 微软雅黑字体路径 # font = pg.font.SysFont("SimHei", 99) # 黑体 text_color = (255, 190, 200) # 字体颜色 rendered_text = font.render(text, True, text_color) rendered_text = font.render(text, True, text_color) while running: clock.tick(99) for event in pg.event.get(): if event.type == pg.QUIT: running = False # 计算文本位置 text_width = rendered_text.get_width() text_height = rendered_text.get_height() text_x = (screenWidth - text_width) // 2 text_y = (screenHeight - text_height) // 2 - 99 screen.fill((20, 20, 30)) # 绘制文本 screen.blit(rendered_text, (text_x, text_y)) if ra.randint(0, 10) == 1: fireworks.append(Firework()) update(screen, fireworks) pg.quit() quit() if __name__ == "__main__": fire()注意:在运行该代码时,请确保你已安装pygame三方库如果没有安装,请使用如下命令进行安装:pip install pygame废话不多说,看效果图:
-